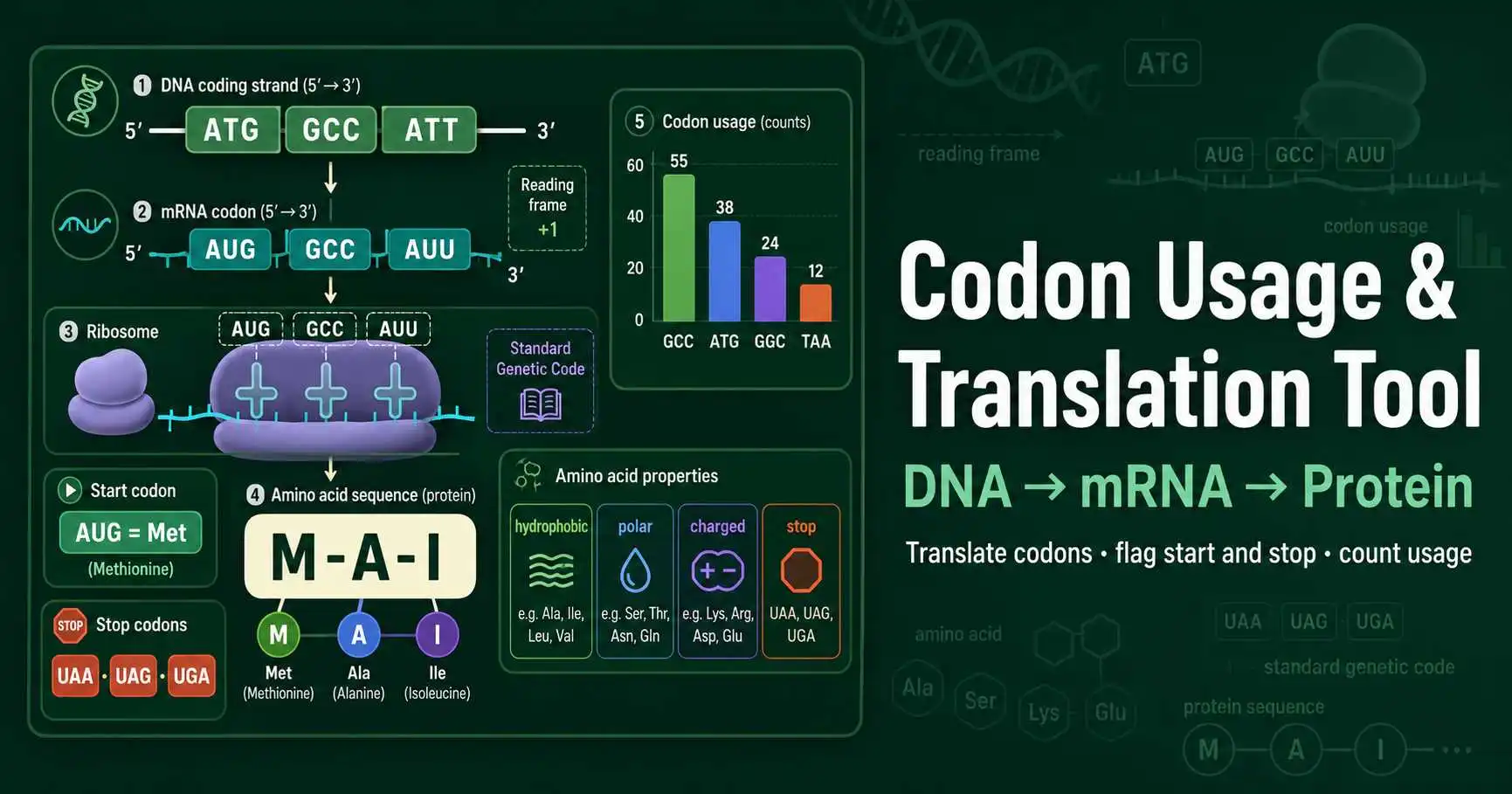
DNA-to-protein translation connects genotype with protein sequence. A single nucleotide change can create a synonymous codon, replace one amino acid, or introduce a premature stop codon. That is why variant annotation starts by locating codons and reading frames.
In cloning and expression work, translation checks catch practical errors before ordering DNA. A missing ATG, a frameshift, or an internal stop codon can prevent protein expression even when the DNA sequence looks long enough. Codon counts also help users notice GC-rich regions that may complicate synthesis or PCR.
In teaching labs, this tool links transcription, translation, and mutation effects. Students can paste the same sequence in three frames and immediately see how codon grouping changes the predicted polypeptide.