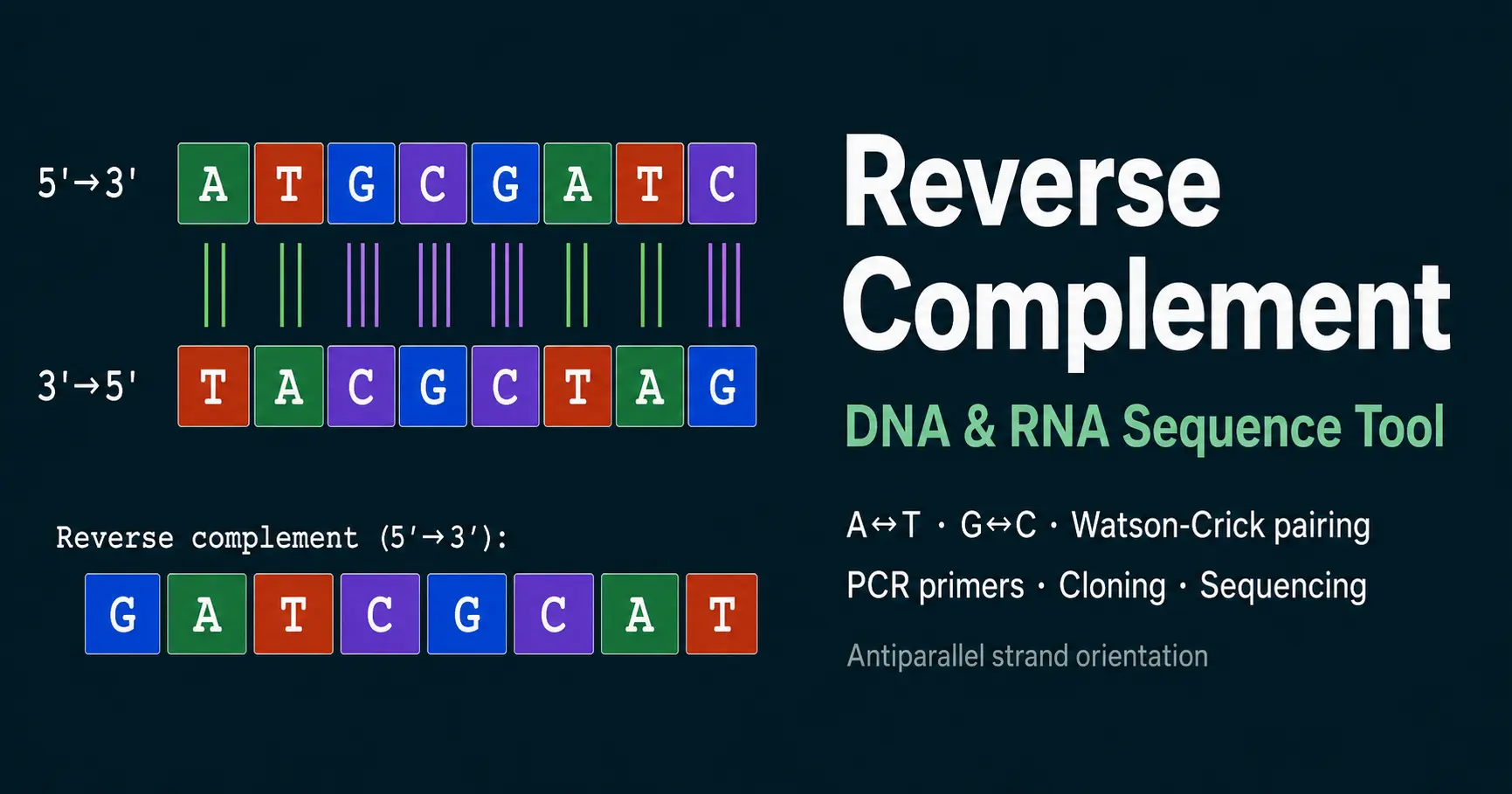
What Is the Reverse Complement — and Why Does It Matter?
The reverse complement is the sequence of the antiparallel DNA strand written in the conventional 5′→3′ direction. Understanding it requires understanding two fundamental properties of the DNA double helix: antiparallel orientation and Watson-Crick base pairing.
DNA is double-stranded. The two strands run in opposite directions — one 5′→3′ and the other 3′→5′ — held together by specific hydrogen bonds between complementary bases. Adenine (A) pairs with thymine (T) using two hydrogen bonds. Guanine (G) pairs with cytosine (C) using three hydrogen bonds. These pairing rules, established by Watson and Crick in their landmark 1953 Nature paper, are the basis for all nucleic acid hybridisation, replication, and transcription.
When you need the sequence of the complementary strand — for example, to design a reverse PCR primer — you cannot simply read the complement left to right. Because the strands are antiparallel, the complementary strand runs in the opposite direction. Reading it in the 5′→3′ convention requires two operations: complementation (replacing each base with its partner) followed by reversal of the entire sequence. The result is the reverse complement.
How to Calculate the Reverse Complement — Step by Step
Write the input sequence 5′ to 3′
Start with your sequence in the standard 5′→3′ direction. Example: 5′-ATGCGATCG-3′
Find the complement of each base
Replace every nucleotide with its Watson-Crick partner: A→T, T→A, G→C, C→G. The order stays the same — this gives the 3′→5′ complementary strand.
Reverse the complement sequence
Flip the entire complement string from end to end. This converts the 3′→5′ strand into a 5′→3′ sequence.
The reverse complement is ready
The final sequence (5′-CGATCGCAT-3′) is the reverse complement. It is the sequence of the bottom strand of the original duplex, written 5′→3′.
Applications of the Reverse Complement in Molecular Biology
PCR primer design
In PCR, the reverse primer must anneal to the antisense strand and prime synthesis toward the forward primer. Its sequence, written 5′→3′, is the reverse complement of the sense strand at the 3′ end of the amplicon. Without the reverse complement, reverse primer sequences cannot be correctly identified. Use our Oligo Analyzer to check Tm and GC content once the sequence is found.
Oligo AnalyzerRestriction enzyme cloning
Restriction enzymes recognise specific palindromic sequences — sequences that are their own reverse complement. EcoRI recognises 5′-GAATTC-3′, whose reverse complement is also 5′-GAATTC-3′. Understanding this palindrome property is essential for planning restriction digest cloning strategies, choosing compatible cohesive ends, and designing insert orientation.
Sanger and next-generation sequencing
Sequencing reads from whole-genome sequencing are generated from both strands. When a read aligns to the reference genome in reverse orientation, it is the reverse complement of the reference sequence at that position. Read alignment software automatically handles this, but understanding the concept is essential for interpreting BLAST results, alignments, and variant calling outputs.
Antisense oligonucleotide design
Antisense oligonucleotides (ASOs), siRNA guide strands, and CRISPR guide RNAs must complement their target sequences. The guide or antisense strand is always the reverse complement of the target mRNA or genomic DNA sense strand. Calculating the reverse complement is therefore the first step in designing any RNA-targeting therapeutic or research tool.
Hybridisation probe design
Southern blots, Northern blots, FISH probes, and microarray probes detect target sequences by hybridisation. A probe that hybridises to a sense strand target must be the reverse complement of that target. The probe's GC content — calculable from the reverse complement sequence — determines its hybridisation stringency.
GC Content CalculatorTranscription and mRNA direction
RNA polymerase reads the template (antisense) strand 3′→5′ and synthesises mRNA in the 5′→3′ direction. The mRNA sequence is therefore identical to the sense (coding) strand, with U replacing T. The reverse complement of the coding strand gives the template strand sequence (3′→5′), which is what RNA polymerase physically reads. Toggle the RNA output option in the calculator to switch from T to U in outputs.
Palindromic Restriction Sites — When a Sequence Is Its Own Reverse Complement
A DNA palindrome is a double-stranded sequence where the top strand 5′→3′ reads identically to the bottom strand 5′→3′ (i.e., the sequence equals its own reverse complement). Most Type II restriction endonucleases recognise such palindromic sequences, allowing them to cut both strands within or near the recognition site using the same protein active site on each strand.
| Enzyme | Recognition site (5′→3′) | Reverse complement | Cut type | Overhang |
|---|---|---|---|---|
| EcoRI | G↓AATTC | GAATTC (palindrome) | 5′ overhang | 4 nt (AATT) |
| BamHI | G↓GATCC | GGATCC (palindrome) | 5′ overhang | 4 nt (GATC) |
| HindIII | A↓AGCTT | AAGCTT (palindrome) | 5′ overhang | 4 nt (AGCT) |
| EcoRV | GAT↓ATC | GATATC (palindrome) | Blunt end | None |
| SmaI | CCC↓GGG | CCCGGG (palindrome) | Blunt end | None |
| NotI | GC↓GGCCGC | GCGGCCGC (palindrome) | 5′ overhang | 4 nt (GGCC) |
↓ indicates the cut position on the top strand. The bottom strand is cut at the corresponding palindromic position.
Frequently Asked Questions — DNA Reverse Complement
What is the reverse complement of a DNA sequence?
Why is the reverse complement needed for PCR primer design?
What is Watson-Crick base pairing?
What does 5’ to 3’ directionality mean in DNA?
What is the difference between complement and reverse complement?
Why are G·C base pairs stronger than A·T base pairs?
How do restriction enzymes use palindromic sequences?
Can I use this calculator for RNA sequences?
Related Tools
GC Content Calculator
Calculate GC%, nucleotide counts, and AT content for any sequence.
Open CalculatorOligo Analyzer
Tm, molecular weight, extinction coefficient for PCR primers.
Open CalculatorOligo Dilution Calculator
Dilute oligonucleotide stocks to working concentrations.
Open CalculatorAllele Frequency Calculator
Hardy-Weinberg equilibrium and population genetics.
Open Calculator