Coefficient of Relationship vs Inbreeding (r vs F)
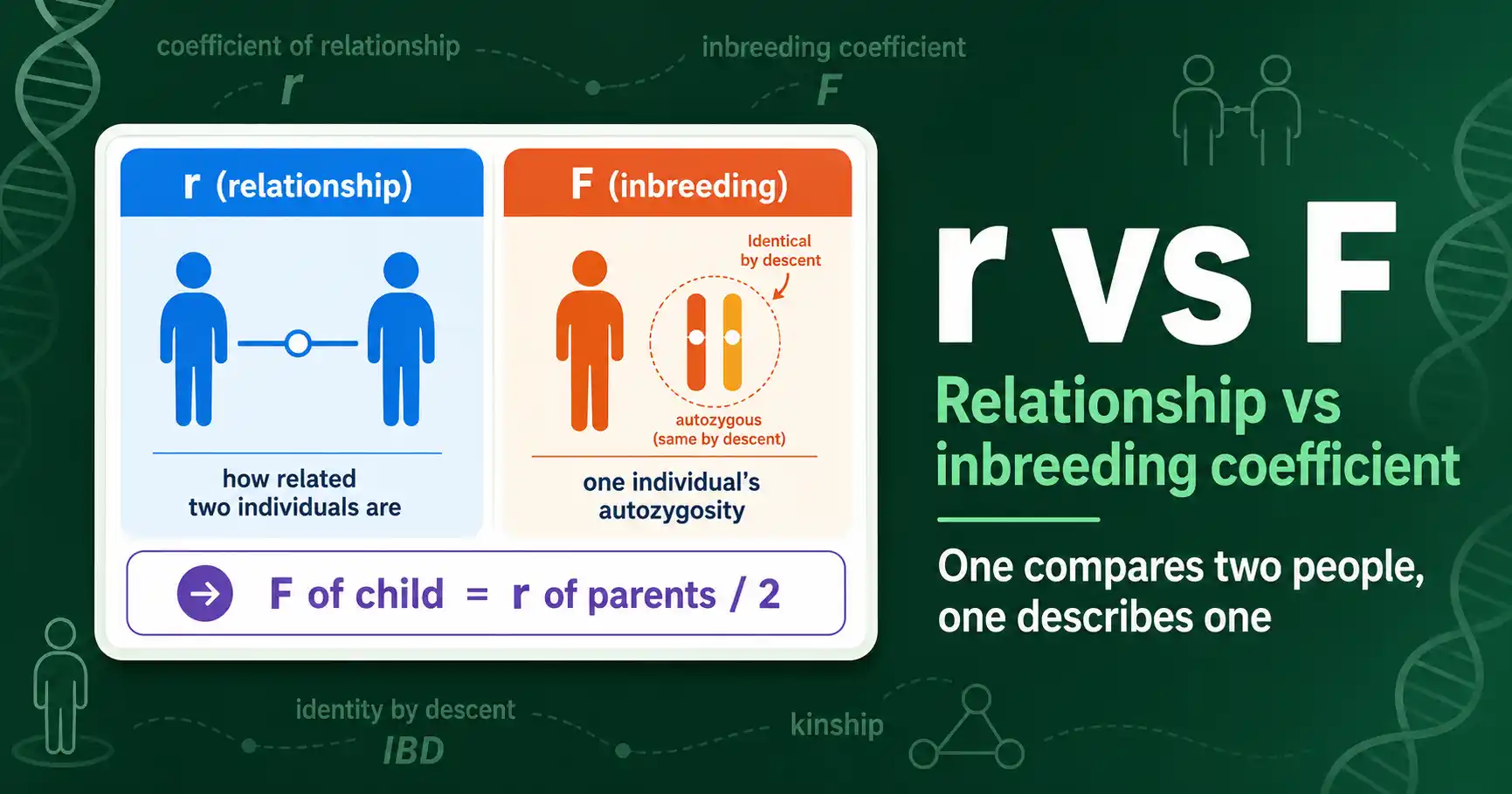
The coefficient of relationship, r, measures how genetically related two individuals are. The inbreeding coefficient, F, measures how inbred a single individual is. That is the core difference: r is about a pair, F is about one person. They are tightly linked, but they answer different questions, and mixing them up is a common mistake.
This guide sorts the two apart and then shows how they connect. It covers what each measures, the simple formula that ties them together, a reference table of standard values, and the related kinship coefficient you will also meet. If you want the full picture of F on its own first, our explainer on what the inbreeding coefficient is covers it.
What Each One Measures
Start with the cleanest distinction. The coefficient of relationship describes the genetic overlap between two individuals. The inbreeding coefficient describes the internal state of one individual.
The coefficient of relationship r is the proportion of alleles two individuals share by descent. A parent and child have an r of 0.5, because the child inherited exactly half its alleles from that parent. Full siblings also have an r of 0.5 on average, because they share half their alleles through their two common parents. The more distant the relationship, the lower the r, falling toward 0 for unrelated individuals.
The inbreeding coefficient F is the probability that one individual's two alleles at a gene are identical by descent. It describes a single individual, not a pair. F rises above 0 only when that individual's parents were related, because related parents can pass down two copies of the same ancestral allele. An individual with unrelated parents has an F of 0, no matter how many relatives it has elsewhere.
So the two coefficients look at different things. Ask "how alike are these two relatives" and you want r. Ask "how likely is this individual to be homozygous from inherited shared ancestry" and you want F. Both were defined by Sewall Wright, r and F together, in his 1922 paper "Coefficients of Inbreeding and Relationship" in The American Naturalist.
The Formula That Links Them
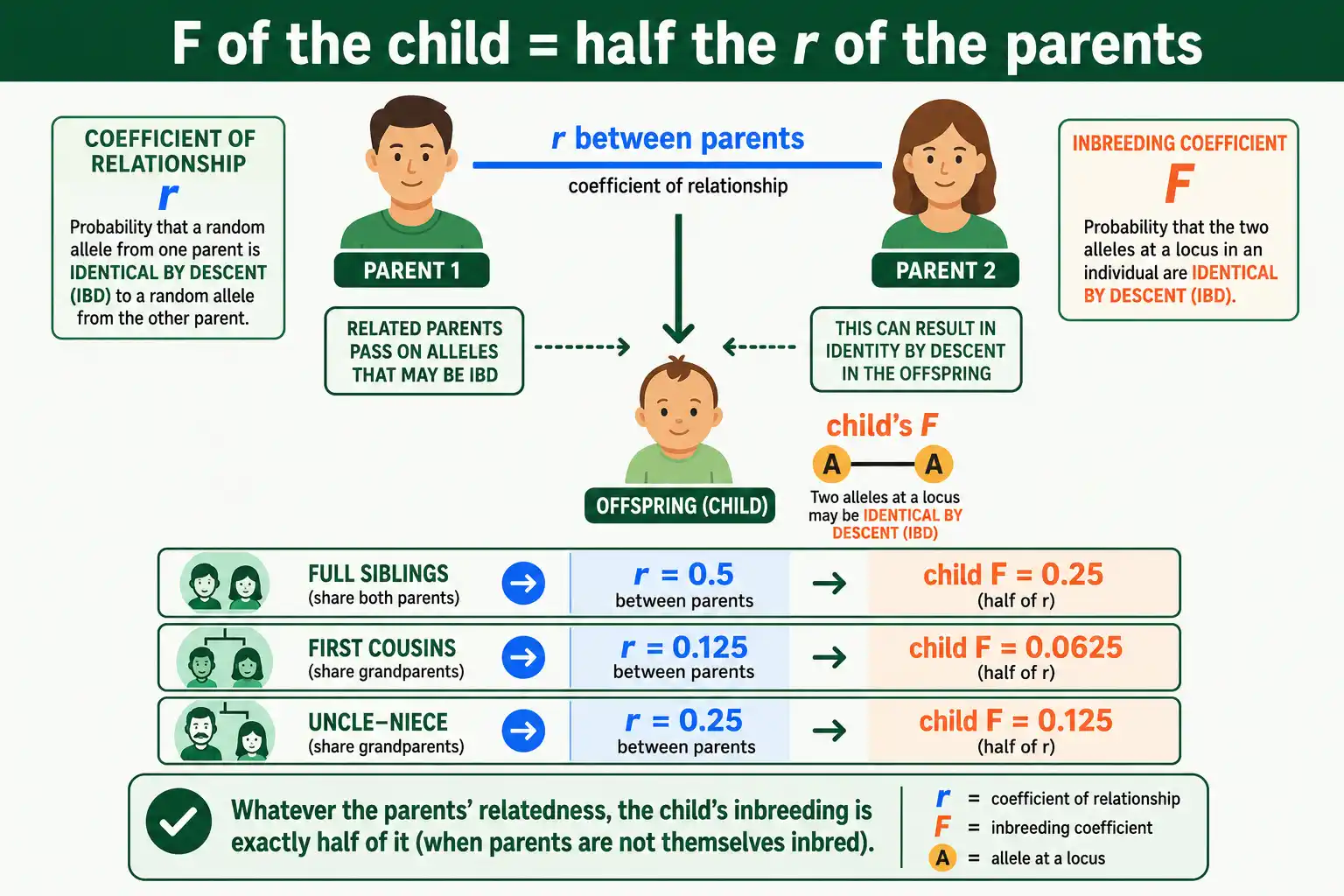
Here is the connection that ties r and F into one framework: an individual's inbreeding coefficient equals half the coefficient of relationship between its two parents.
Written simply, F of the child equals r of the parents divided by 2. The logic is direct. If two parents share a fraction r of their alleles by descent, then when they reproduce, the chance their child receives two copies of the same ancestral allele is exactly half of that shared fraction. So the child's autozygosity, its F, is half the parents' relatedness, their r.
The relationship works in both directions and explains the standard numbers at a glance. Full siblings have an r of 0.5, so their child has an F of 0.25. First cousins have an r of 0.125, so their child has an F of 0.0625. Uncle and niece have an r of 0.25, so their child has an F of 0.125. Every inbreeding coefficient in the textbooks is just half of a relationship coefficient. One caution: this clean halving holds when the parents are not themselves inbred. At higher, compounded levels of inbreeding the exact relationship gets more involved, but for most real cases the simple halving is accurate.
How the Coefficient of Relationship Is Calculated
You compute r much like F, by tracing paths through common ancestors, with one difference in the exponent. For each path connecting the two individuals through a shared ancestor, raise one-half to the number of links in that path, then sum across all paths.
Take full siblings. They connect through two shared parents, giving two paths. Each path runs from one sibling up to a shared parent and back down to the other, a path of two links, contributing one-half squared, or 1/4. Two paths at 1/4 each sum to 1/2, so r is 0.5. First cousins connect through two shared grandparents by longer paths, each contributing 1/16, summing to 1/8, so r is 0.125.
The rule mirrors the inbreeding calculation, which is no accident: both descend from Wright's path-coefficient method. The practical difference is that r counts paths between two separate individuals, while F counts loops through the two parents of one individual. Because the child's loop is exactly the parents' connecting path plus one extra link down to the child, the child's F comes out as half the parents' r, the link from the formula section made concrete.
Relatedness and Shared DNA
In the era of consumer DNA tests, the coefficient of relationship has a familiar cousin: the percentage of DNA two people share. They are closely connected, with one wrinkle worth understanding.
The coefficient of relationship predicts the expected fraction of DNA two relatives share by descent. A parent and child share 50 percent, full siblings 50 percent on average, first cousins about 12.5 percent. These match the r values exactly, which is why consumer tests can estimate how two people are related from the fraction of DNA they share.
The wrinkle is variation. The r value is an expectation, an average over many pairs. Any specific pair varies around it because of how chromosomes are randomly shuffled and recombined during reproduction. Two full siblings share 50 percent on average, but a given pair might share anywhere from roughly 38 to 61 percent. Parent and child are the exception: they always share essentially exactly 50 percent, because a child inherits precisely one of each chromosome pair from each parent, with no sampling variation. This is why DNA tests can distinguish a parent-child pair from full siblings even though both have an r of 0.5: the parent-child sharing is fixed, while sibling sharing scatters. The same expected-versus-realized distinction applies to F, where a pedigree predicts the average and genomic data measures the actual figure.
A Side-by-Side Table
The standard values are easier to hold in a table. This shows r between the two individuals and the F of a child they would produce.
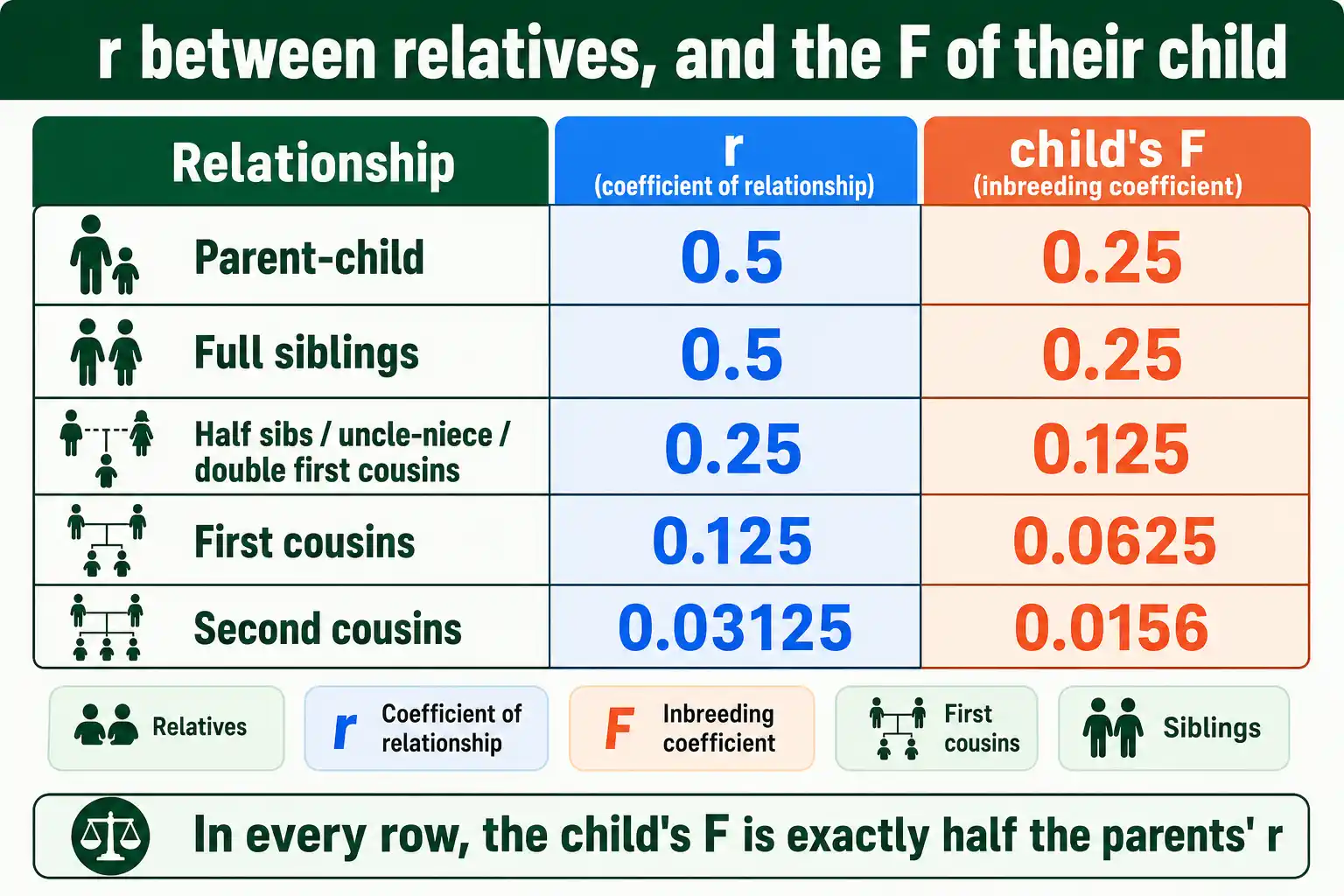
| Relationship | Coefficient of relationship (r) | F of their child |
|---|---|---|
| Identical twins | 1.0 | not applicable |
| Parent and child | 0.5 | 0.25 |
| Full siblings | 0.5 | 0.25 |
| Half siblings | 0.25 | 0.125 |
| Uncle-niece / aunt-nephew | 0.25 | 0.125 |
| Double first cousins | 0.25 | 0.125 |
| First cousins | 0.125 | 0.0625 |
| Second cousins | 0.03125 | 0.015625 |
Two patterns stand out. In every row, the child's F is exactly half the parents' r, the formula in action. And several different relationships share the same r: half siblings, uncle-niece, and double first cousins all sit at 0.25, because different ancestral paths can add up to the same total overlap. The relationship label matters less than the number of shared paths through common ancestors.
The Kinship Coefficient
A third term appears constantly alongside these two: the kinship coefficient, sometimes called the coancestry or coefficient of kinship. It is worth knowing because it unifies r and F.
The kinship coefficient between two individuals is the probability that an allele picked at random from one is identical by descent to an allele picked at random from the other. Its defining trick is this: the kinship coefficient between two individuals exactly equals the inbreeding coefficient that their offspring would have. In other words, kinship looks forward to the hypothetical child's F.
This makes kinship the bridge term. The coefficient of relationship r is approximately twice the kinship coefficient, and the offspring's F equals the kinship coefficient directly. So all three measures, r, F, and kinship, are versions of the same underlying quantity, the probability of identity by descent, viewed from different angles: between two individuals (kinship), scaled up for relatedness (r), or inside one individual (F). Population geneticists often work in kinship coefficients precisely because they convert so cleanly into the other two. The shared foundation is the same identity-by-descent idea explored in our guide on calculating the inbreeding coefficient.
A subtle point makes kinship especially useful. An individual's kinship with itself is not 0.5 but a bit more when the individual is inbred, because its own two alleles already have some chance of being identical by descent. Specifically, self-kinship equals one-half times the quantity one plus that individual's F. For an outbred individual with an F of 0, self-kinship is exactly 0.5, but for an inbred one it is higher. This is why kinship matrices, the tables breeders and geneticists build for whole populations, automatically carry inbreeding information on their diagonal: each individual's entry with itself encodes its own F. From one matrix, you can read relatedness between any pair off the off-diagonal and inbreeding of any individual off the diagonal, which is why the kinship coefficient is the workhorse of computational pedigree analysis.
Why the Distinction Matters
Keeping r and F separate is not pedantry. Using the wrong one gives the wrong answer to a real question.
In animal breeding, r and F do different jobs. Breeders use r to predict how similar two animals are, which matters for selecting breeding stock with desired traits. They use F to track the inbreeding of individual animals and the herd, because rising F predicts inbreeding depression. A breeder who confused the two might select for relatedness while ignoring accumulating inbreeding, or vice versa.
In evolutionary biology, r is the star of kin selection. William Hamilton's famous rule, that an altruistic behavior spreads when the relatedness r times the benefit to the recipient exceeds the cost to the actor, comes from his 1964 work on the evolution of social behavior and uses the coefficient of relationship directly. It explains why animals help close kin: a high r means helping a relative passes on shared genes. F plays no role here; this is purely a between-individuals question, so r is the right tool.
The classic illustration is the worker bee. A worker that never reproduces still passes on her genes by helping her mother, the queen, raise sisters, and in honeybees the unusual genetics make sisters share a high proportion of their alleles, which strengthens the payoff of cooperation. The point is general: behaviors that sacrifice an individual's own reproduction can still spread if they help relatives who carry the same genes, and r is the exact measure of how much benefit those relatives represent. Confusing this with F would make the theory incoherent, because inbreeding of one individual has nothing to do with whether helping a sibling pays off.
In human genetics, F is the one that predicts recessive-disease risk in a child, while r describes how related the parents are. A genetic counselor uses the parents' r to find the child's F, then assesses risk from that F. Each coefficient has its lane, and the formula linking them is what lets you move between the two.
Frequently Asked Questions
Is the coefficient of relationship the same as the inbreeding coefficient?
No. The coefficient of relationship r measures how related two individuals are, the share of alleles they hold in common by descent. The inbreeding coefficient F measures one individual's autozygosity, the chance its two alleles are identical by descent. They are linked, since a child's F equals half its parents' r, but they describe different things.
How do you convert between r and F?
A child's inbreeding coefficient is half the coefficient of relationship between its parents: F equals r divided by 2. So parents with an r of 0.5, like full siblings, produce a child with an F of 0.25. This holds when the parents are not themselves inbred.
What is the relationship coefficient for siblings?
Full siblings have a coefficient of relationship of 0.5, meaning they share on average half their alleles by descent, the same r as a parent and child. Half siblings, who share only one parent, have an r of 0.25.
Two Coefficients, One Idea
The coefficient of relationship and the inbreeding coefficient measure different things from the same root. The coefficient of relationship r captures how genetically alike two individuals are; the inbreeding coefficient F captures how likely a single individual is to carry two identical-by-descent alleles. The formula F equals half of r, applied to a child's parents, links them, and the kinship coefficient unifies both as views of one quantity: the probability of identity by descent.
Knowing which to reach for is the practical payoff. Use r for relatedness questions, including kin selection and breeding-stock similarity, and use F for autozygosity and recessive-disease risk. To turn a known parental relationship into a child's exact F, you can calculate F from the relationship directly, and to see where these numbers come from in a family tree, our guide on the inbreeding coefficient from a pedigree traces them step by step.